Hi,
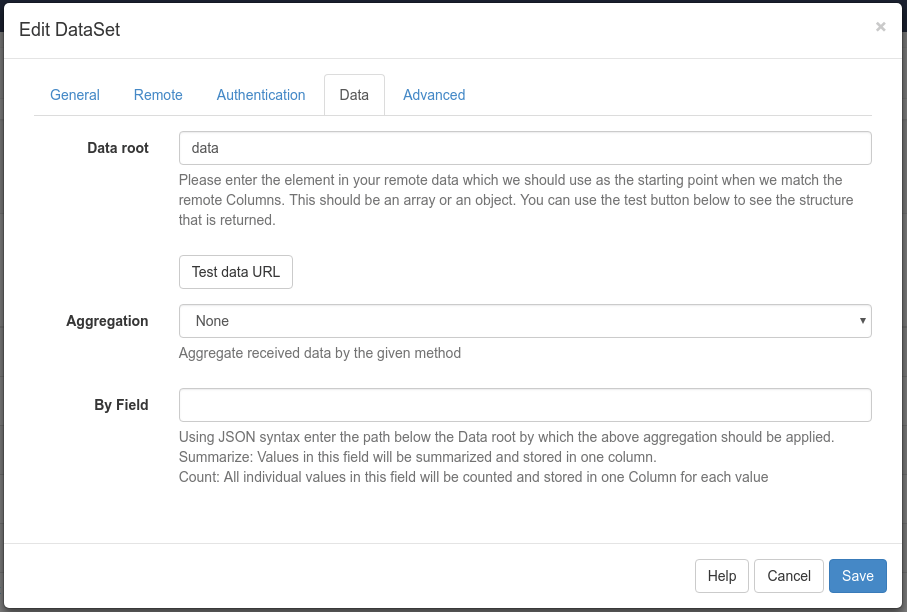
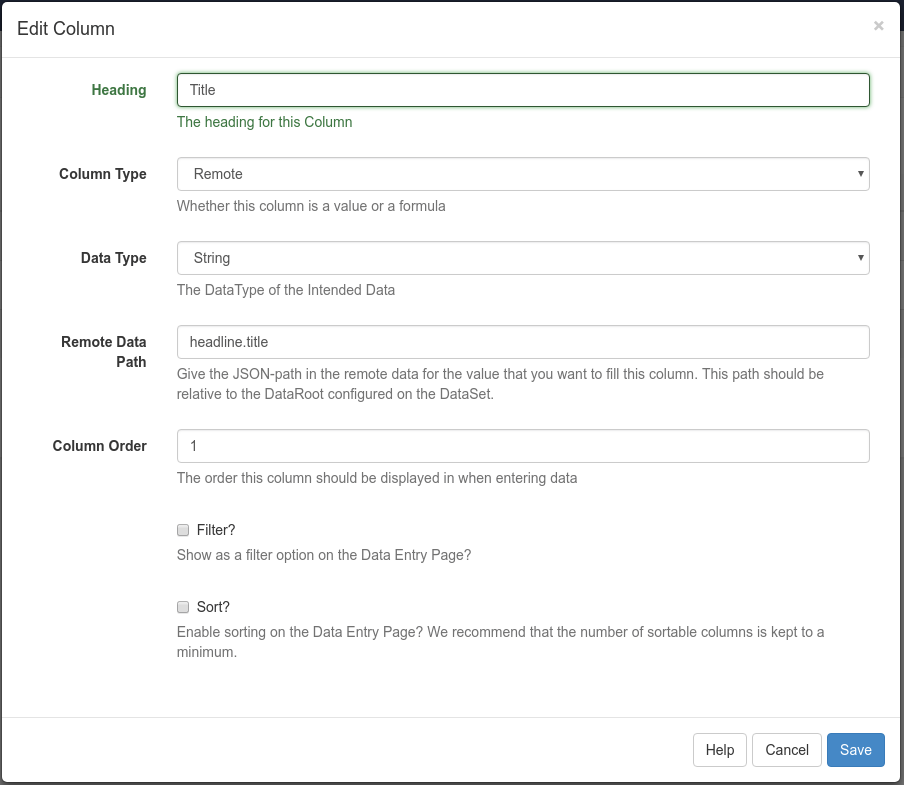
I’ve got the following piece of JSON, from which I want to ingest $data.headline.title, $data.headline.translations.urls.url and $data.image.url into a dataset as separate columns.
I tried with “data” as Data Root, but cannot get any values into the columns - probably because the arrays are nested.
Is there any way to do this ?
In JSONPath format I see that e.g. $.data.[*].headline.translations[0].urls.[0].url should work, however it doesn’t pick anything up in Xibo
Any suggestions ?
Thanks
Rene
{
"start" : 0,
"rows" : 2,
"total" : 2,
"data" : [
{
"headline" : {
"headlineId" : "13097310",
"status" : "publish",
"priority" : 1,
"pinned" : 1,
"title" : "Blabla title1",
"startTime" : 1548191454017,
"endTime" : 1548796254017,
"tenant" : "comms",
"translations" : [
{
"locale" : "en_US",
"abstractText" : "BlaBla text",
"title" : "Blabla item title",
"urls" : [
{
"contentType" : "text/html",
"url" : "google.com",
"mobile" : true
}
]
}
],
"image" : {
"layout" : "hdSquare",
"height" : 300,
"width" : 300,
"imageContentId" : "050a8880",
"url" : "blabla#com#ff#jpg",
"altText" : "Blabla alt text",
"backgroundColor" : "#000000",
"foregroundTextColor" : "#ffffff",
"imageLibraryId" : "04b2cb90"
},
"limitsTo" : [
{}
]
},
"metrics" : {
"rank" : 10000500
}
},
{
"headline" : {
"headlineId" : "13097311",
"status" : "publish",
"priority" : 1,
"pinned" : 1,
"title" : "Blabla title1",
"startTime" : 1548191454017,
"endTime" : 1548796254017,
"tenant" : "comms",
"translations" : [
{
"locale" : "en_US",
"abstractText" : "BlaBla text",
"title" : "Blabla item title",
"urls" : [
{
"contentType" : "text/html",
"url" : "google#com",
"mobile" : true
}
]
}
],
"image" : {
"layout" : "hdSquare",
"height" : 300,
"width" : 300,
"imageContentId" : "050a8881",
"url" : "blabla#com#ff#jpg",
"altText" : "Blabla alt text",
"backgroundColor" : "#000000",
"foregroundTextColor" : "#ffffff",
"imageLibraryId" : "04b2cb91"
},
"limitsTo" : [
{}
]
},
"metrics" : {
"rank" : 10000500
}
}
]
}